


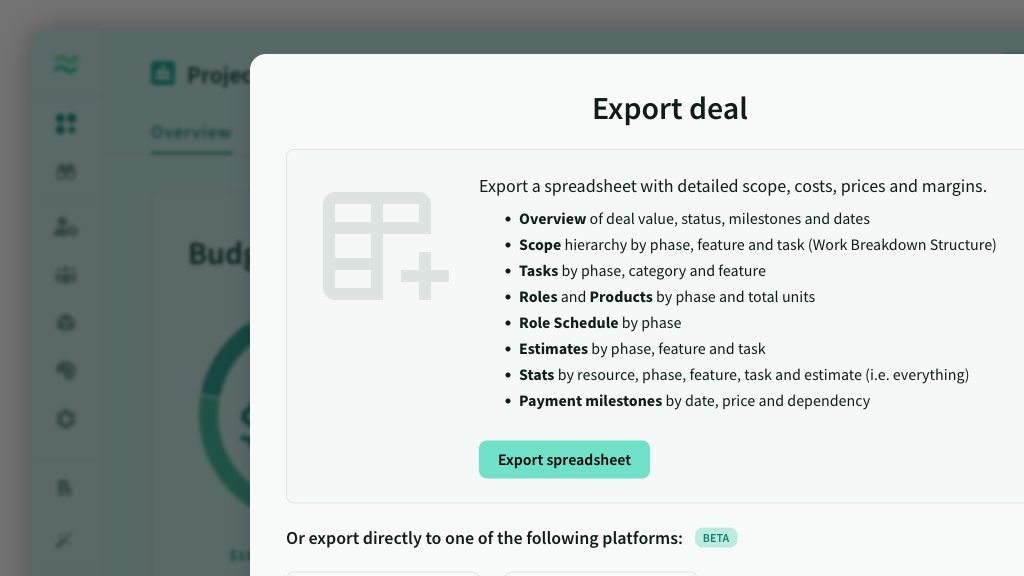
Everyone wants “more accurate estimates.” Very few teams build a system that makes estimates improve.
The goal isn't perfect forecasts. The goal is controlled variance:
- you know where you're consistently wrong,
- you can explain why,
- and you get less wrong over time.
This guide describes a lightweight estimation improvement loop you can run without turning your org into a bureaucracy.
The estimation accuracy loop (simple version)
Run this loop per project (or per phase, for long projects):
- Measure: collect a few metrics consistently
- Review: a 30-45 minute post-project review
- Update: change your model (roles, rate cards, contingency, scope patterns)
- Standardise: capture reusable scope patterns and guardrails
If you only do one step, do Update. Insight without model change doesn't improve estimates.
Step 1: pick 2-3 metrics you'll actually track
Don't start with dashboards. Start with a small set of metrics that drive decisions.
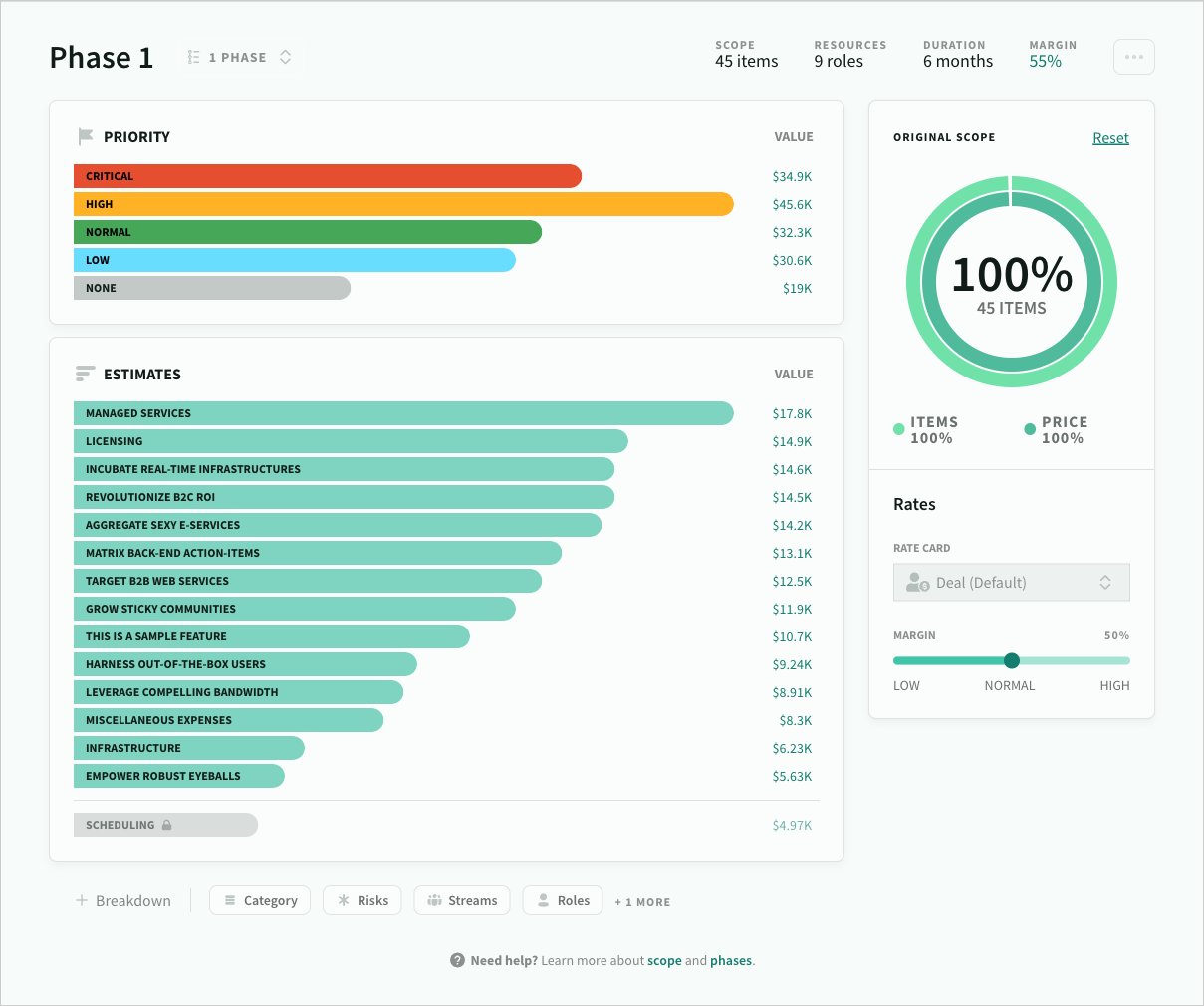
Metric A: estimate vs actual variance (by phase and total)
Track effort variance as a percentage:
- (\text{variance} = (\text{actual} - \text{estimate}) / \text{estimate})
Then split it by phase (or major workstream).
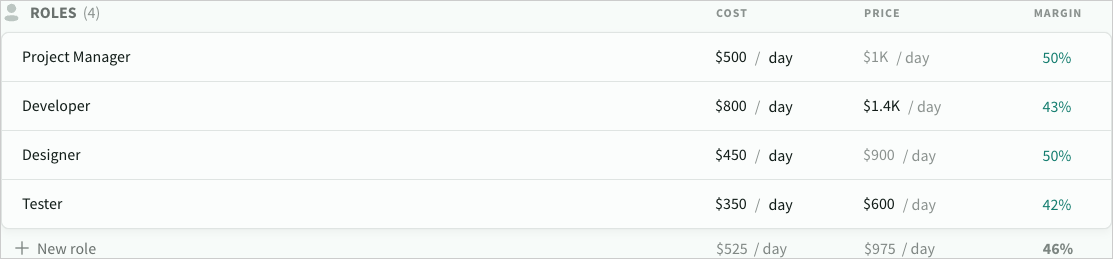
Metric B: bias by role / stream
Most teams aren't “bad at estimating.” They're consistently wrong in a few areas:
- testing is under-estimated
- PM/BA overhead is hidden
- integration work explodes late
- security/compliance isn't costed until it's urgent
This is where role/stream analysis pays off.
Metric C: change-request rate
If you're constantly adding scope, you don't have an estimation problem — you have a qualification and baseline problem.
Track:
- number of meaningful changes
- where they came from (buyer, internal, dependencies)
- whether they were priced/traded
Step 2: run a post-project review that fits in 45 minutes
The review is not a blame session. It's a calibration session.
Agenda:
- What changed: scope, timeline, dependencies, stakeholders
- Where we were wrong: top 3 drivers of variance
- What we missed: hidden tasks, non-functional requirements, approvals
- What to change: update the model (not just “be more careful”)
A useful rule:
If the output of the review is “communicate better,” you didn't go deep enough.
Step 3: update the model (the part most teams skip)
Update role costs/prices when reality shifts
If delivery uses different seniority mixes, or your cost base changes, your role model must reflect it.
Related docs:
Calibrate contingency and risk rules
Contingency exists for known unknowns. If your high-risk items routinely explode, your contingency range is too low (or your risk classification is too optimistic).
Related doc:
Standardise schedule assumptions
Many “estimation misses” are really schedule misses:
- onboarding overhead not counted
- parallelisation assumptions are unrealistic
- delivery cycle rounding is inconsistent (weeks vs sprints vs months)
Related doc:
Capture scope patterns (your biggest ROI)
Turn recurring surprises into reusable patterns:
- integration checklist (data, auth, rate limits, environments)
- QA and release checklist (test plan, UAT, rollout, monitoring)
- security/compliance pack (threat model, pen test support, policies)
- operational readiness (runbooks, alerting, handover)
The point is not “more documentation.” The point is preventing repeated blind spots.
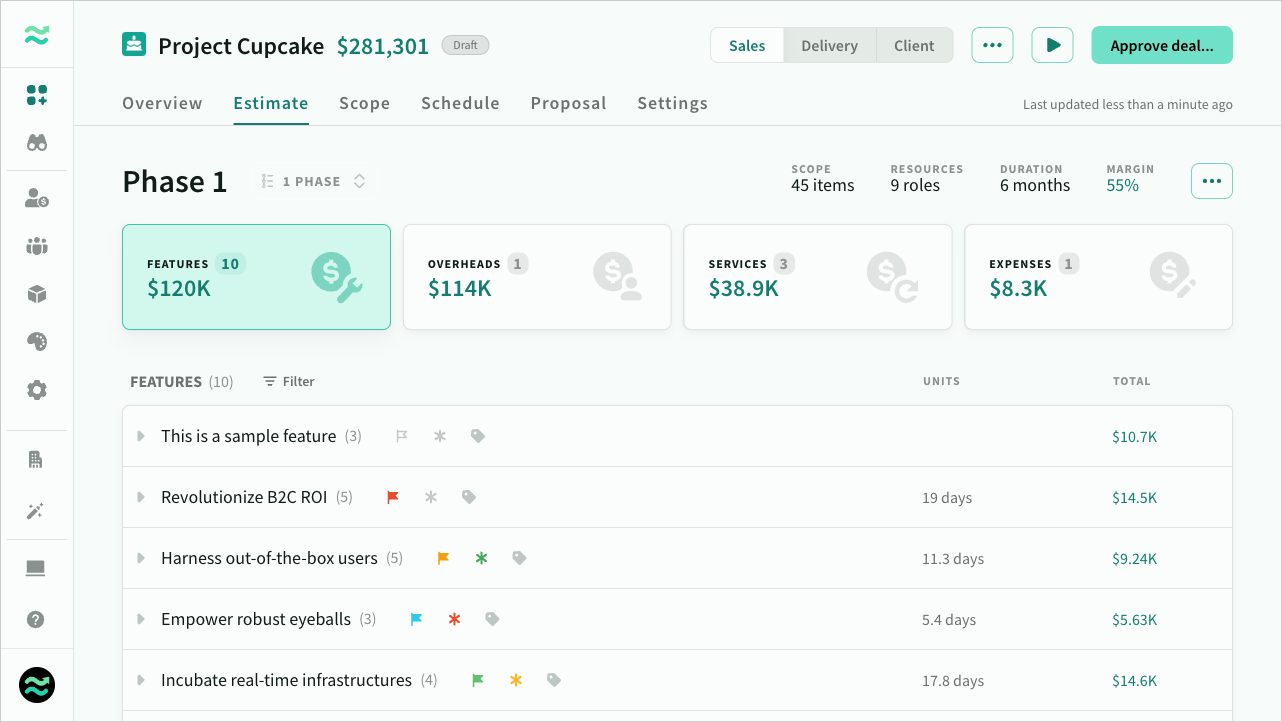
Step 4: measure using exports (without reinventing your stack)
You don't need a bespoke analytics pipeline to start.
Export the deal and use it for:
- role totals per phase
- task lists with risk/priority/contingency
- scope structure for WBS imports
- milestone/payment structure for commercial validation
Related docs:
Keep your workspace consistent as the model evolves
As you improve your resources and settings (roles, streams, products, capacity, contingency), you need a controlled way to update existing deals.
Related doc:
Make “what changed” visible (so trust increases)
When estimates change, stakeholders want to know why.
Create versions at meaningful moments:
- before/after a major scope change
- before/after a rate/margin adjustment
- before/after timeline compression
Related doc:
A lightweight template you can reuse
If you want a simple repeatable template, copy this structure into your internal notes:
- Context: what we sold, what we delivered
- Baseline: assumptions, exclusions, dependencies
- Variance drivers: top 3 (with evidence)
- Fixes: role model changes, risk rules, scope patterns
- Guardrails: “next time we will…”
Closing thought
Better estimates come from better systems, not better intentions.
If you measure a few things consistently and make small model changes every project, estimation stops being a stressful art—and becomes a compounding advantage.

